
AI platforms carry a fundamental limitation. They can only respond based on what they absorbed during training. That training data has a fixed cutoff date, which creates a real problem for brands and businesses alike. They need AI systems to deliver accurate, current, and domain-specific answers. Retrieval-Augmented Generation (RAG) solves this problem directly. It connects a large language model to up-to-date external knowledge sources before generating a response.
This connection dramatically improves the accuracy and trustworthiness of the AI’s output. For content marketers and digital strategists, understanding RAG is now essential. It determines how AI search platforms decide which sources to cite when answering user queries.
What Is Retrieval-Augmented Generation and How Does It Work?
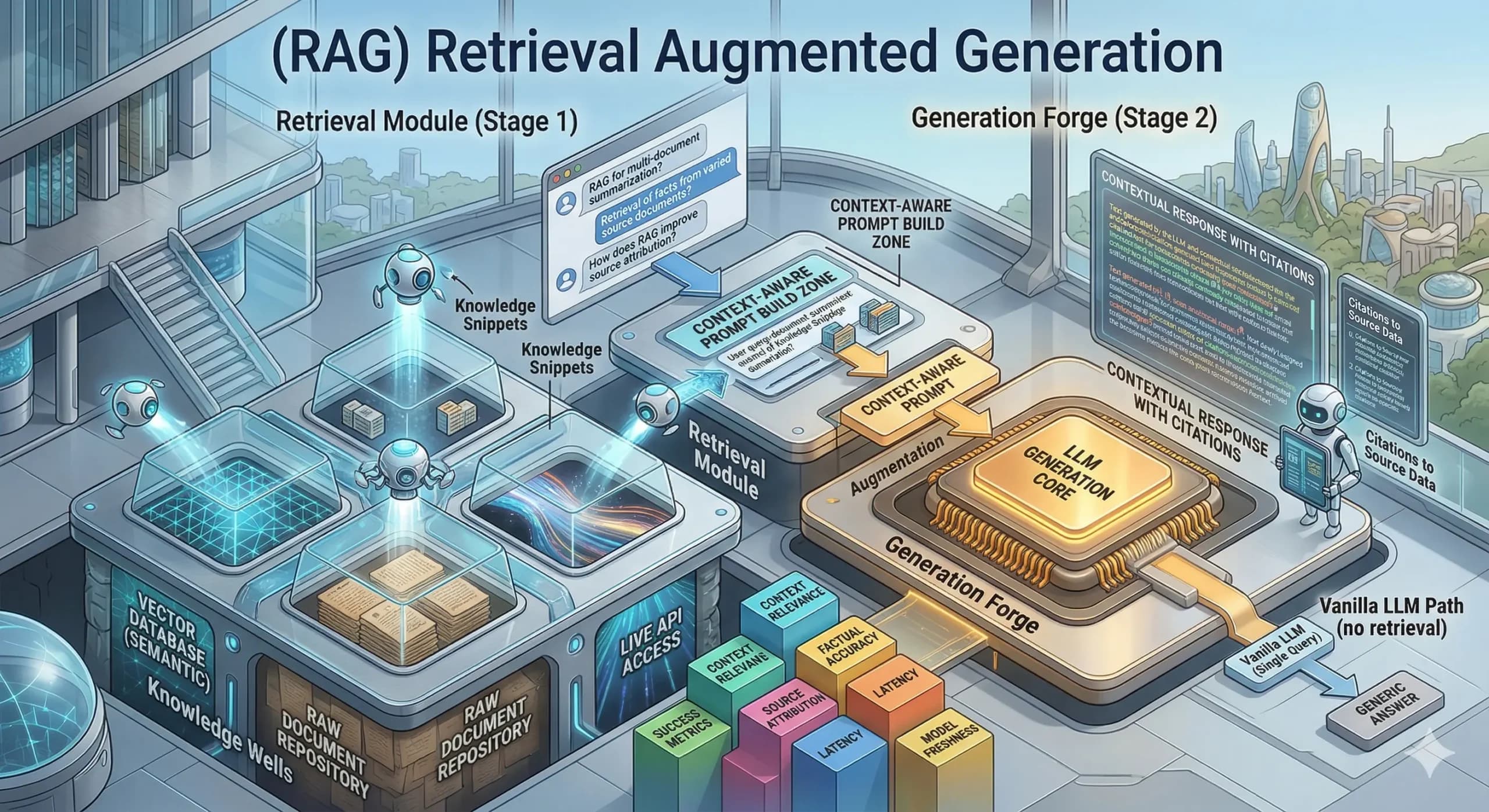
Retrieval-Augmented Generation (RAG) is an AI framework. It enhances large language models by connecting them to external knowledge bases before generating a response. Rather than relying only on training data, a RAG system retrieves relevant documents in real time. It then uses that retrieved content to ground the answer it produces for the user.
The process follows a clear sequence. A user submits a query. The RAG system converts it into a vector, i.e., a numerical representation the system searches with. The system then scans a knowledge base for documents semantically similar to the query. It selects the most relevant sources and feeds them into the language model alongside the original question.
The language model then synthesizes a response. It draws from its training knowledge and the retrieved documents simultaneously. It often cites the external sources that informed its answer. This retrieve-then-generate workflow powers AI search platforms like Perplexity and Google AI Overviews. Well-structured, authoritative content earns citations more consistently than generic or outdated material.
Why Does RAG Matter for Content Marketing and Brand Visibility?
RAG directly determines which content an AI platform retrieves and cites. It forms the core mechanism behind Answer Engine Optimization and GEO strategies that brands invest in today.
When a RAG-powered platform generates a response, it evaluates candidate documents for relevance, authority, recency, and structural clarity. Content that scores well across these dimensions earns a citation in the AI output. Content that is poorly structured or outdated gets excluded from the response pool entirely. This exclusion happens regardless of how well it ranks in traditional search results.
- Content structure becomes a retrieval signal: RAG systems favor content organized for extraction. They prioritize clear headings, concise answer paragraphs, and direct statements the system can lift and synthesize without losing meaning. A content strategy built around RAG-friendly formatting consistently improves AI citation rates across major platforms.
- Original information gives the retriever a specific reason to select content: RAG systems have no reason to cite a source that restates what is already available elsewhere. Original research and proprietary data give the retrieval component a specific reason to select a brand’s content over a competitor’s during the scoring phase.
- Content recency directly improves retrievability: RAG systems actively favor fresh content. Their purpose is to ground AI responses in accurate, current information. Regular content updates directly improve a brand’s position in the retrieval pool of RAG-powered platforms.
- E-E-A-T signals strengthen the probability of citation: RAG systems retrieve from demonstrably credible sources. Author credentials, cited sources, and third-party brand mentions all increase the likelihood that a brand’s content is selected during the retrieval scoring phase.
What Are the Four Key Components of a RAG System?
A RAG system operates through four interconnected components. Together, they determine the quality, accuracy, and relevance of the generated output for any given user query.
- The knowledge base: The external repository that the RAG system queries when a user submits a prompt. It can include internal documents, product databases, web-indexed content, and research papers. The quality and organization of this knowledge base directly determines how accurately the system retrieves relevant content.
- The retriever: This component converts the user query into a vector. It then searches the knowledge base for semantically similar content. It evaluates relevance mathematically and selects the most contextually appropriate documents to pass to the language model. Stronger retrieval quality leads to more accurate final responses for the user.
- The integration layer: This component coordinates the overall RAG pipeline. It combines retrieved documents with the original user query through prompt engineering techniques. It instructs the language model to synthesize retrieved information into a coherent, accurate response that accurately represents the source material.
- The generator: This is the large language model that produces the final response. It simultaneously draws on retrieved documents and its own training knowledge. Models such as GPT-4, Claude, Gemini, and Llama commonly serve as generators. They combine external evidence with broad language understanding to produce accurate, citation-supported outputs.
What Are the Benefits and Challenges of Retrieval-Augmented Generation?
RAG transforms what large language models can accomplish. It carries both significant advantages and practical challenges that organizations must navigate thoughtfully to achieve reliable results.
Benefits of RAG
- Reduced AI Hallucinations: RAG decreases instances of false information by grounding every response in verifiable, retrieved documents. This approach improves factual accuracy for high-stakes queries in the finance and healthcare industries.
- Dynamic Knowledge Updates: Organizations can keep their AI systems current without the high cost of retraining a model from scratch. The knowledge base updates independently whenever new information becomes available in the data source.
- Improved Source Transparency: RAG provides users with specific citations within each generated response to increase overall trust. These citations allow audiences to verify information directly, especially in regulated and high-credibility industries.
- Cost-Effective Specialization: This technology enables targeted applications by connecting a general-purpose model to a specialized knowledge base. A single model serves multiple industry contexts without requiring separate, expensive training runs.
Challenges of RAG
- Risk of Contextual Misinterpretation: Systems occasionally retrieve factually correct documents that are contextually misleading for the specific query. The language model may then produce a response that combines accurate data with an incorrect conclusion.
- Dependence on Data Quality: The quality of the final output depends heavily on the organization and structure of the knowledge base. Poorly structured or outdated source documents consistently produce weak responses, regardless of the model’s capabilities.
- Complex Infrastructure Requirements: Implementing a production-grade pipeline requires technical infrastructure like vector databases and orchestration frameworks. These requirements present a significant barrier for smaller organizations without dedicated AI engineering resources.
- Multidimensional Performance Evaluation: Measuring performance requires evaluating retrieval precision, generation accuracy, and citation quality simultaneously. This process is far more complex than tracking a single performance metric, as traditional search allows.
How Does RAG Influence Which Content AI Platforms Cite?
RAG-powered platforms follow the same retrieve-then-synthesize workflow when responding to user queries. Perplexity, Google AI Overviews, and ChatGPT with browsing capabilities all operate this way. The content a brand produces directly determines whether it enters the retrieval pool for relevant queries. It also determines whether it ultimately earns a citation in the AI response.
Content structured for extraction scores higher during the retrieval phase. Direct answers near the top of each section, clear entity definitions, and specific data points all improve retrieval scores. This is precisely why content marketing services focused on AEO and GEO produce measurably stronger AI citation rates. Content built purely around traditional keyword density strategies performs significantly weaker in RAG-powered environments.
Brands that publish original research, expert analysis, and proprietary data give RAG systems a specific, unique reason to retrieve their content. Competitor material that covers the same ground in generic terms earns fewer citations as a result. In a RAG-powered search environment, information gain functions as one of the most powerful signals a brand can optimize. It refers to the degree to which a piece of content adds something new and verifiable to the topic. Brands can strengthen this signal through a focused digital marketing strategy.
At Scribblers India, the team uses RAG principles to build GEO and AEO content strategies that help brands earn consistent citations across AI search platforms.
Connect with the team today to make content AI-retrieval-ready.
FAQs
How is Retrieval-Augmented Generation different from simply fine-tuning a language model on custom data?
Fine-tuning trains a model on new data and permanently updates its internal parameters. This requires significant time and computational cost. RAG retrieves external documents at query time without modifying the model itself. It is faster to update and more cost-effective to maintain. It also suits knowledge bases that change frequently far better than full fine-tuning cycles do.
What content performs best for retrieval by a Retrieval-Augmented Generation system?
Content that is clearly structured, factually accurate, and organized around specific questions performs best. Documents with original data points and direct answer statements near the top of each section consistently score higher. Clear attribution to credible authors also improves the relevance ranking used to determine which sources a RAG system passes to its language model for synthesis.
Does RAG completely eliminate hallucinations in AI-generated responses?
RAG significantly reduces hallucinations by grounding responses in retrieved documents. It does not eliminate them entirely. If the system retrieves a misleading source, the final response can still contain errors. If the language model misinterprets the context of an accurate document, errors can also occur. Source quality in the knowledge base remains critically important to RAG output reliability at all times.
How can a content marketing team optimize for RAG-powered platforms?
Teams should prioritize original research, answer-first content structure, and direct entity definitions. They should also schedule regular content updates throughout the year. Publishing unique, verifiable information rather than restating publicly available material gives RAG systems a specific retrieval reason. This approach measurably improves the likelihood of earning a citation in the AI-synthesized response.
Does RAG apply to personal branding and thought leadership strategies as well?
Executives and founders who publish consistent, expert-led content across authoritative platforms increase their RAG retrieval chances. AI systems retrieve their content more often when users query topics in their domain. A strong personal branding strategy that produces original insight at scale builds entity authority. RAG-powered platforms use this authority to evaluate citation worthiness for both individuals and the brands they represent.


